We spent a morning trying to figure out why containers in a new installation of Swarm just couldn’t talk to each other. Overlay network looked fine. Firewall looked fine. You could get from the host to the container, just not from the container to a container on the other server. So … here’s a bug where your swarm (i.e. the thing you do when you want docker stuff to run across more than one server) cannot actually, ya know, talk to the other servers. Sigh!
Category: Containerized Development and Deployment
Kubernetes / Containerd Image Pull Failure
We are in the process of moving our k8s environment from CentOS 7 to RHEL 8.8 hosts — which means the version of pretty much everything involved is being updated. All of the pods that use images from an internal registry fail to load. At first, we were thinking DNS resolution … but the test pods we spun up all resolved names appropriately.
2023-09-13 13:48:34 [root@k8s ~/]# kubectl describe pod data-sync-app-deployment-78d58f7cd4-4mlsb -n streams
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 15m default-scheduler Successfully assigned kstreams/data-sync-app-deployment-78d58f7cd4-4mlsb to ltrkarkvm1593-uos
Normal Pulled 15m kubelet Container image "docker.elastic.co/beats/filebeat:7.9.1" already present on machine
Normal Created 15m kubelet Created container filebeat
Normal Started 15m kubelet Started container filebeat
Normal BackOff 15m (x3 over 15m) kubelet Back-off pulling image "imageregistry.example.net:5000/myapp/app_uat"
Warning Failed 15m (x3 over 15m) kubelet Error: ImagePullBackOff
Normal Pulling 14m (x3 over 15m) kubelet Pulling image "imageregistry.example.net:5000/myapp/app_uat"
Warning Failed 14m (x3 over 15m) kubelet Failed to pull image "imageregistry.example.net:5000/myapp/app_uat": rpc error: code = Unknown desc = failed to pull and unpack image "imageregistry.example.net:5000/myapp/app_uat:latest": failed to resolve reference "imageregistry.example.net:5000/npm/app_uat:latest": get registry endpoints: parse endpoint url: parse " http://imageregistry.example.net:5000": first path segment in URL cannot contain colon
Warning Failed 14m (x3 over 15m) kubelet Error: ErrImagePull
Warning DNSConfigForming 31s (x73 over 15m) kubelet Search Line limits were exceeded, some search paths have been omitted, the applied search line is: kstreams.s vc.cluster.local svc.cluster.local cluster.local mgmt.windstream.net dsys.windstream.net dnoc.windstream.net
I have found “first path segment in URL cannot contain colon” in reference to Go — and some previous versions at that. There were all sorts of suggestions for working around the issue — escaping the colon, starting with “//”, adding single or double quotes around the string, downgrading to a version of Go not impacted by the problem. Nothing worked.
A few hours with no progress, I thought some time investigating “how can I work around this?” was in order. Kubernetes is using containerd … so it should be feasible to pre-stage the image in containerd and then set our imagePullPolicy values to IfNotPresent or Never
To pre-seed the images in containerd so that they are available for kubernetes run:
ctr -n=k8s.io image pull -u $REGISTRYUSER:$REGISTRYPASSWORD --plain-http imageregistry.example.net:5000/myapp/app_uat:latest
This must be run on every k8s worker in the environment — if a pod tries to spin up on server2 but you’ve only seeded the image file on server1 … the pod will fail to load. We need to update this staged image every time we make changes to the application. Better than not using the new servers, so that’ll just be the process for a while.
Ultimately, the problem ended up being that a few of the workers had a leading space in the TOML file for the repo — how that got there, I have no idea. But once there was no longer extraneous white-space, we could deploy the pods without issue. Now that it’s working “as designed”, we deleted the pre-seeded image using:
ctr -n=k8s.io images rm ImageNameHere
K8s 1.24.12 Upgrade
Trying to upgrade our dev Kubernetes environment to 1.24.12 … and we encountered what seems to be a fairly common error — unknown service runtime.v1alpha2.RuntimeService
kubeserver:~ # kubeadm init
I0323 13:53:26.492921 55320 version.go:256] remote version is much newer: v1.26.3; falling back to: stable-1.24
[init] Using Kubernetes version: v1.24.12
[preflight] Running pre-flight checks
[WARNING Firewalld]: firewalld is active, please ensure ports [6443 10250] are open or your cluster may not function correctly
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR FileAvailable--etc-kubernetes-manifests-kube-apiserver.yaml]: /etc/kubernetes/manifests/kube-apiserver.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-kube-controller-manager.yaml]: /etc/kubernetes/manifests/kube-controller-manager.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-kube-scheduler.yaml]: /etc/kubernetes/manifests/kube-scheduler.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-etcd.yaml]: /etc/kubernetes/manifests/etcd.yaml already exists
[ERROR CRI]: container runtime is not running: output: E0323 13:53:26.741684 55340 remote_runtime.go:948] "Status from runtime service failed" err="rpc error: code = Unimplemented desc = unknown service runtime.v1alpha2.RuntimeService"
time="2023-03-23T13:53:26-05:00" level=fatal msg="getting status of runtime: rpc error: code = Unimplemented desc = unknown service runtime.v1alpha2.RuntimeService"
, error: exit status 1
[ERROR DirAvailable--var-lib-etcd]: /var/lib/etcd is not empty
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher
We found a lot of people online with the same issue who (1) removed the config.toml and tried again, (2) changed the SystemdCGroup setting in the config, or uninstalled and reinstalled some/all of the components until it worked. Unfortunately, removing or modifying the config didn’t help. And removing and reinstalling everything wasn’t particularly appealing. However, we noticed that the same error was reported directly from containerd:
kubeserver:~ # crictl ps
E0323 13:53:07.061777 55228 remote_runtime.go:557] "ListContainers with filter from runtime service failed" err="rpc error: code = Unimplemented desc = unknown service runtime.v1alpha2.RuntimeService" filter="&ContainerFilter{Id:,State:&ContainerStateValue{State:CONTAINER_RUNNING,},PodSandboxId:,LabelSelector:map[string]string{},}"
FATA[0000] listing containers: rpc error: code = Unimplemented desc = unknown service runtime.v1alpha2.RuntimeService
Looking at the plugins, there were some in an error state
kubeserver:~ # ctr plugins ls
TYPE ID PLATFORMS STATUS
io.containerd.content.v1 content - ok
io.containerd.snapshotter.v1 aufs linux/amd64 skip
io.containerd.snapshotter.v1 btrfs linux/amd64 skip
io.containerd.snapshotter.v1 devmapper linux/amd64 error
io.containerd.snapshotter.v1 native linux/amd64 ok
io.containerd.snapshotter.v1 overlayfs linux/amd64 error
io.containerd.snapshotter.v1 zfs linux/amd64 skip
So … it seemed reasonable to look for errors in the messages log from containerd. And, yeah, we had all sorts of errors. Including a rather scary one about reformatting the file system!
Mar 23 13:24:51 kubeserver containerd: time="2023-03-23T13:24:51.726984260-05:00" level=warning msg="failed to load plugin io.containerd.snapshotter.v1.overlayfs" error="/var/lib/containerd/io.containerd.snapshotter.v1.overlayfs does not support d_type. If the backing filesystem is xfs, please reformat with ftype=1 to enable d_type support"
That would do it — we have a dedicated partition for the k8s stuff … and that volume is formatted the right way — xfs_info confirmed ftype=1
kubeserver:~ # xfs_info /kubernetes/
meta-data=/dev/mapper/kubernetes-kubernetes isize=512 agcount=4, agsize=131071744 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0 spinodes=0
data = bsize=4096 blocks=524286976, imaxpct=5
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal bsize=4096 blocks=255999, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
However containerd doesn’t really know anything about this volume, does it? The default location that containerd wants to use isn’t set up to support d_type. Editing /etc/containerd/config.toml, root now tells containerd to use our special partition for ‘stuff’ …
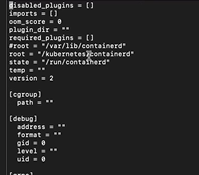
And we were able to run kubeadm init without error. Everything came up as it should have, and our k8s server was upgraded!
Running a Docker Container without *RUNNING* The Container
I needed to get files from a container image that I couldn’t actually start (not enough memory, and finding a box with more memory wasn’t a reasonable option) — fortunately, you can override the container entrypoint to start the container without actually running whatever the container would normally run.
docker run -ti --entrypoint=bash imageName
Useful K8s Commands
Shell into pod
kubectl exec -it <pod_name> -- /bin/bash
Quick Docker Test
I’m building a quick image to test permissions to a folder structure for a friend … so I’m making a quick note about how I’m building this test image so I don’t have to keep re-typing it all.
FROM python:3.7-slim
RUN apt-get update && apt-get install -y curl --no-install-recommends
RUN mkdir -p /srv/ljr/test
# Create service account
RUN useradd --comment "my service account" -u 30001 -g 30001 --shell /sbin/nologin --no-create-home webuser
# Copy a bunch of stuff various places under /srv
# Set ownership on /srv folder tree
RUN chown -R 30001:30001 /srv
USER 30001:30001
ENTRYPOINT ["/bin/bash", "/entrypoint.sh"]
build the image
docker build -t “ljr:latest” .
Run a transient container that is deleted on exit
docker run –rm -it –entrypoint “/bin/bash” ljr
Docker – Changing an Existing Container
I’ll start by acknowledging that, of course, you could just redeploy the container with the settings you want now. The whole point of containerized development is that anything “good” should either be part of the deployment settings or data persisted outside of the container. So, in theory, redeploying the container every day shouldn’t really be detectable. Even when you didn’t deploy the original container (i.e. you don’t have the Dockerfile or docker run command handy to tweak as needed), you can reverse engineer what you need from docker inspect. But sometimes? It’s quicker/easier/more convenient to just fix what you need to within the existing container. And it is possible to do so.
The trickiest part is finding the right file to edit.
# cd into docker container definition folder
cd /var/lib/docker/containers/
# find the guid for the container you want to edit
docker ps
# Find the corresponding folder name
ls -al | grep bc9dc66882af
# cd into that folder
cd bc9dc66882af18f59c209faf10031fe21765571d0a2fe4a32a768a1d52cc1e53
# Edit the config.v2.json file for the container
vi config.v2.json
# And, finally, restart docker
systemctl stop docker
systemctl start docker

Docker – Reporting IP Addresses of Containers
Quick command to report on the IP addresses of all containers running on a Docker server:
docker ps | awk 'NR>1{ print $1 }' | xargs docker inspect -f '{{range .NetworkSettings.Networks}}{{$.Name}}{{" "}}{{.IPAddress}}{{end}}'

Reverse engineering Kubernetes YAML’s
Ideally, the definitions for Kubernetes objects are all safely stored in your code repository — you can easily revert back to the previous, working iteration, you can see who changed what, and you’ve got a copy of it all available if super electromagnet man takes a stroll through the data center. Ideally.
Here, in the real world, we took over management of a k8s implementation that’s been in service for about a year now. And, fortunately, the production YAMLs are all in the repo. The development system, on the other hand, isn’t. Logic dictates that the config would be similar, but it’s always good to check.
I wrote a quick script to dump YAML files for all of the configmaps, cron jobs, deployments, horizontal pod autoscaling, jobs, persistent volumes, persistent volume claims, secrets, service accounts, services, and stateful sets.
#!/bin/bash
nsbase="namespace/"
for ns in $(kubectl get namespaces -o=name)
do
ns=${ns#${nsbase}}
for n in $(kubectl get --namespace=$ns -o=name configmap,cronjob,deployment,hpa,job,pv,pvc,secret,serviceaccount,service,statefulset)
do
yamlfile="${ns}/${n}.yaml"
mkdir -p $(dirname ${ns}/${n})
kubectl get --namespace=$ns -o=yaml $n > $yamlfile
done
done
Building a Docker Image Without Internet Access (kinda)
We’ve been moving a bunch of servers into magic cloudy land. A move which comes with a whole lot of additional security restrictions (and accompanying marketing that the cloud is so much more secure … uhh, no … any host to which you used a keylogged jump server to access & it had absolutely no access to the internal or external network without a specific request and firewall rule would be equally secure. You just haven’t bothered with all of those controls before!). As such, we cannot just pull an image from Docker Hub. We also cannot just use apt-get to install/update packages.
So … how can you build a Docker image with updated software for use on these locked down boxes? Bit of a trick question — you cannot. You can, however, build such an image elsewhere and then export/import the image.
Build the image using your Dockerfile
docker build -t my_app_base .
Then export the image you created
docker save my_api_base | gzip > myapp_image.tar.gz
Download the TGZ file and transfer it to your restricted-access host. Then import the image
docker load < myapp_image.tar.gz
Verify the image loaded successfully
[user@server ~]$ docker images REPOSITORY TAG IMAGE ID CREATED SIZE localhost/my_app_base latest 5z8e35z99d5z 19 minutes ago 995 MB <none> <none> 5zdbcfz6393z About an hour ago 1.01 GB
Now use docker run with your my_app_base:latest image to create a running container based on the image.