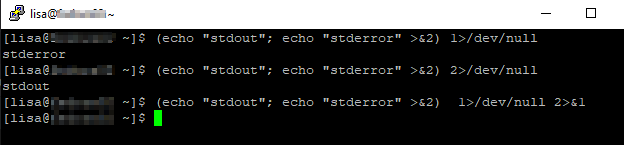
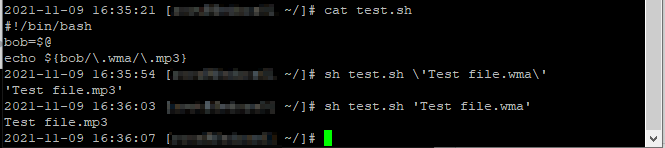
The rsync utility was meant to be used to sync files across the network — to or from an rsync server. For some time, I had a group of friends who shared documents off of my rsync server. Anyone with access could run an rsync command and sync their computer up with the group’s documents. With the advent of online file storage and collaborative editing, this was no longer needed. But I still use rsync to make sure my laptop has a local copy of a folder on the server. Mount /path/to/folder/contents/to/copy to the SMB or NFS share, and the following rsync command ensures the laptop’s /path/to/where/contents/should/be/placed has an exact mirror of the contents of the server folder
rsync –archive –verbose –update –delete “/path/to/folder/contents/to/copy/” “/path/to/where/contents/should/be/placed/”
–archive is a grouping of:
-r recursive
-l copy symlinks
-p preserve permissions
-t preserve modification timestamps
-g preserve group
-o preserve owner
–devices preserve device files (su only)
–specials preserve special files